Your Code Moves at Machine Speed. Your Docs Don’t.
The New Era: Agentic Coding
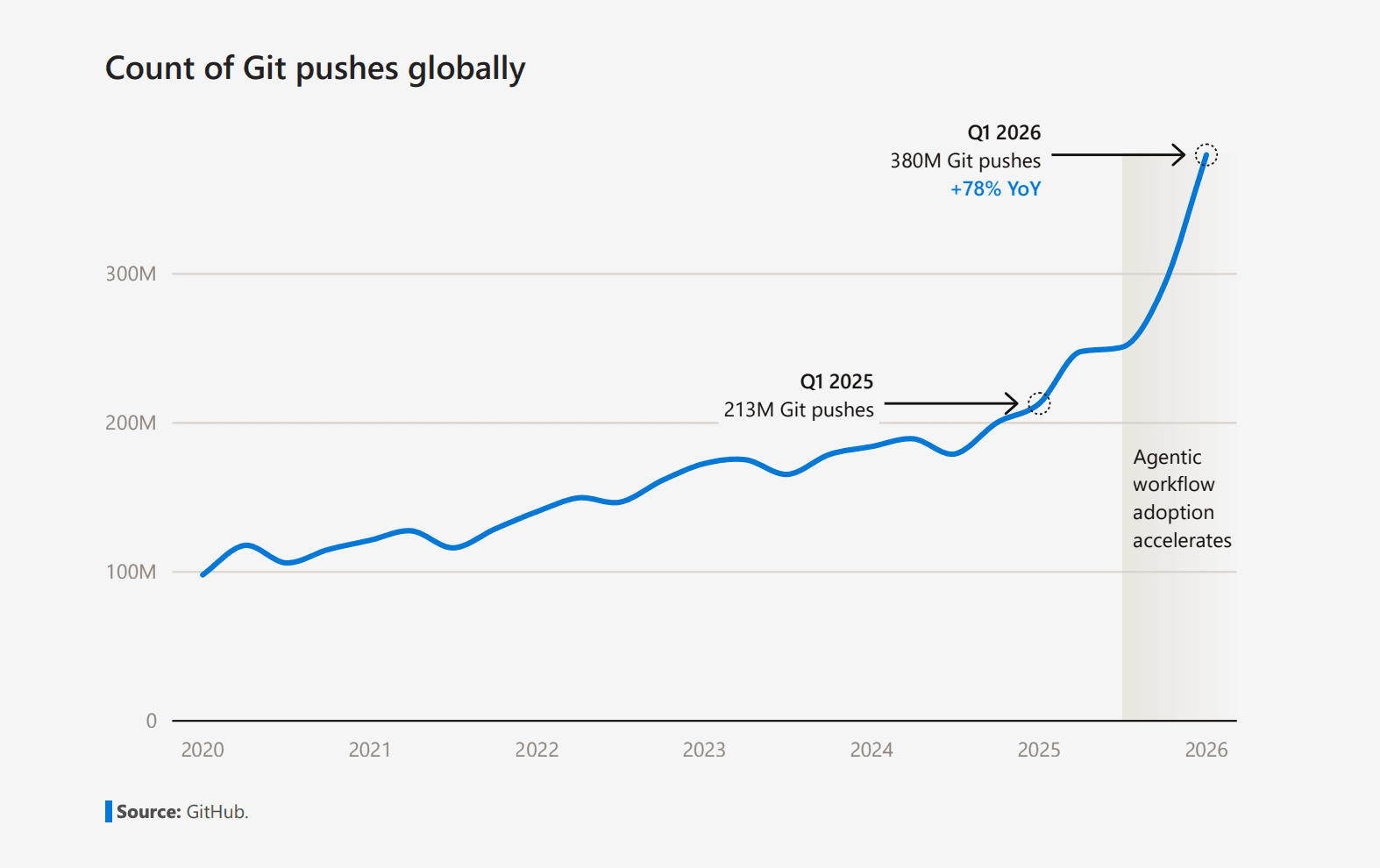
We have entered a new era of agentic coding where Git pushes has increased by 78% over the last 12 months. But alongside this high-profile tectonic shift in engineering, something quiet has happened: the comprehension layer fell behind the generation layer. Engineers can now produce code faster than they—or anyone on the team—can fully read it. Technical documentation, which was already the slowest-moving artifact in any repo, now lags two or three release cycles behind a codebase that nobody has fully internalized. And it’s becoming the most expensive form of technical debt nobody is putting on a board deck.
Technical documentation has not meaningfully changed in 20 years. It is essentially a human translation task. An engineer writes a feature, understands the architectural “why,” and eventually translates that intent into external documentation for customers and partners. Using a human translator didn’t work perfectly, but teams could make do with the combination of imperfect tech docs and tribal knowledge.
Before this new era of agentic coding, code moved at human speed. So using a human translator to document the code was physically possible. Because of the exponential increase in deployment frequency, it is no longer humanly possible to read and understand the entire surface area of what shipped and translate that into tech docs. Code now moves at machine speed. But we are still asking humans to explain a machine’s logic at a machine’s pace. It’s a losing battle.
The Documentation Tax on the P&L
The consequences of asking humans to explain a machine’s logic at a machine’s pace show up in 3 places on a P&L: lost sales, support costs, and silent churn.
Lost Sales
The most expensive failure mode is the one that happens above the funnel. A developer evaluating your product opens your quickstart, copies the code sample, runs it, and gets a stack trace. The function signature changed two releases ago. The argument order is reversed. The import path moved. They spend forty minutes debugging documentation that should have been ground truth.
They don’t file a ticket. They close the tab. The evaluation ends.
Your CRO never hears about it, because the prospect never entered the pipeline. Tech doc accuracy has quietly become a top-of-funnel filter for technical buyers, and it filters silently. You don’t get a lost-deal review; you get an absence of deals you should have had.
Support Costs
Technical documentation is supposed to scale: write it once, serve it to everyone. When it’s wrong, that same scaling mechanism runs in reverse—one bad doc, N identical tickets. Every wrong code sample is a multiplier on your support load.
The cost compounds at the staffing layer. Support engineers can deflect questions to tech docs when they trust the source material. When they don’t, they stop pointing customers at the tech docs and start answering everything by hand, spiking support costs. Tickets that should resolve at the CS tier escalate to engineering. The most expensive labor in the organization ends up spending their afternoon identifying why a snippet doesn’t run.
Beyond the ticket, correcting a wrong tech doc requires someone to confirm what the code actually does—which means reading and reasoning about a codebase that has outrun the team’s collective understanding of it. So either the tech doc stays wrong and the ticket queue keeps refilling, or an engineer diverts half a day to rebuilding context to update the tech docs.
Ticket volume and lost engineering productivity both harm the P&L. The ticket volume is just the visible part.
Silent Churn
Every wrong code sample creates two cost lines. The first is the support ticket you can see—a customer patient enough to ask why the example doesn’t work. The second is from existing customers who hit the same thing and didn’t bother to write in—they just stop using the product and quietly leave at renewal. In fact, CX research has shown that for every customer who files a complaint, roughly 25 others remain silent.1
The tickets are annoying. The silent churn is the actual bleed.
And this is the world before AI agents started consuming your docs at scale.
Documentation as Infrastructure
When Claude Code, Cursor, GitHub Copilot, or any coding agent fetches your technical documentation, it treats your tech docs as ground truth and acts on them. If your getting-started example references a function that no longer exists, the agent will write code against the phantom API and ship it into the customer’s repo.
Stripe, Cloudflare, Anthropic, and Expo are just a few examples of companies that now publish parallel markdown versions of their tech docs specifically so coding agents can consume them cheaply and accurately. A whole class of tooling—Context7 being the most visible example—has emerged specifically to fetch current, version-specific technical documentation from official sources and feed it directly into coding agents at query time.
In the new era of agentic coding, tech docs have become infrastructure. Tech docs are now foundational infrastructure for the agent layer of the stack, which means the bar for tech doc accuracy has moved from “good enough for the new hire” to “good enough for a machine to execute against.” The catch-22 is that agentic coding has made accurate tech docs both essential and elusive—at least with our current manual documentation practices.
The Etchblok Thesis: Continuous Documentation
Just as we moved from manual testing to CI/CD, we must move from manual documentation to Continuous Documentation.
Etchblok was founded to transform technical documentation, future-proofing it to move at the pace of AI. Our thesis is simple: If code is moving at AI-speed, technical documentation must move with it. And because AI agents now consume those docs as infrastructure, accuracy is no longer a courtesy to human readers—it’s a prerequisite for machines. To meet both demands, tech docs must be tethered directly to the codebase: version-controlled, automated, and synchronized with every PR and commit. See my co-founder Vik Advani’s blog post about why Etchblok’s approach to Continuous Documentation is technically superior and why LLMs alone can’t fix the documentation problem.
The era of manual documentation is over. It’s time to embrace Continuous Documentation.
References
- 1.John A. Goodman, Strategic Customer Service (AMACOM, 2009). Based on data from the Technical Assistance Research Programs (TARP) Institute. ↑